{kind=link}
推理时间减少70%!前馈3DGS「压缩神器」来了,浙大Monash联合出品
在增强现实(AR)和虚拟现实(VR)等前沿应用领域,新视角合成(Novel View Synthesis,NVS)正扮演着越来越关键的角色。3D 高斯泼溅(3D Gaussian Splatting,3DGS)凭借其革命性的实时渲染能力和卓越的视觉质量,迅速成为 NVS 领域备受关注的技术方案。
现有的前馈 3D 高斯泼溅(Feed-Forward 3D Gaussian Splatting,3DGS)模型,虽然在实时渲染和高效生成 3D 场景方面取得了显著进展,但仍存在一些关键缺陷。
比如编码器容量有限,难以处理密集的多视角输入。
而ZPressor,一种即插即用的轻量级模块——可以无缝集成到现有的前馈 3DGS 模型中,增强模型密集视角扩展性和性能。
在 36 个输入视图下提升 4.65dB,推理时间减少 70%,显存占用减少 80%,并拓展可输入的视图数目到接近 500 个。

信息过载:前馈 3DGS 的 " 甜蜜负担 "
深入分析现有前馈 3DGS 模型的架构,可以发现其核心症结在于编码器容量的有限性。
当输入视图变得密集时,编码器难以有效处理随之而来的 " 信息过载 ",导致计算成本飙升。
这种现象并非偶然,而是源于场景总信息量(即所有视图特征的联合熵)中存在大量冗余信息。
在特征提取之后,如何去除不相关信息,同时保留其预测能力,是高效利用输入视图信息的关键。
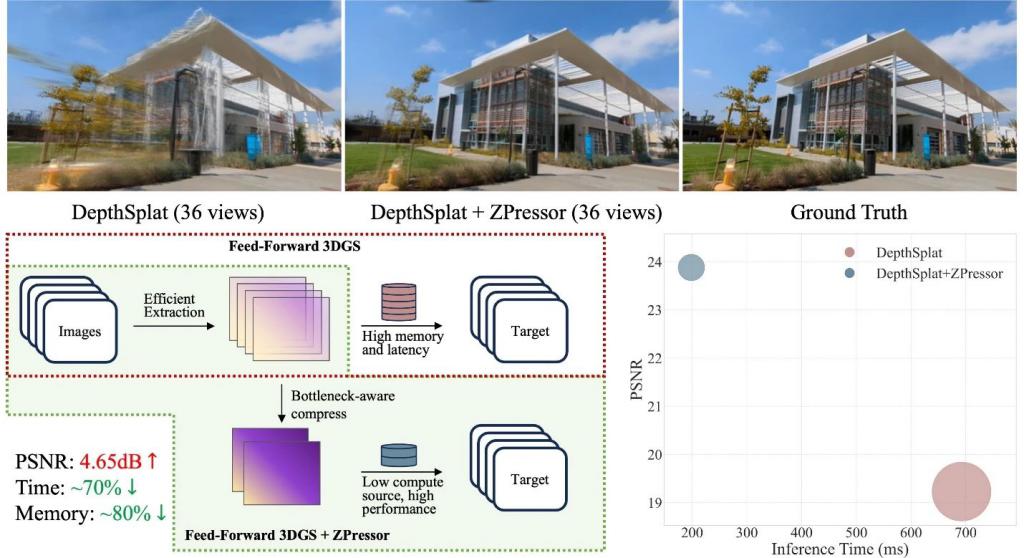
以当前最先进的模型 DepthSplat 为例,实验结果表明,随着输入视图数量的增加,模型性能会显著下降,同时计算成本也急剧攀升。例如,在处理 36 个输入视图时,DepthSplat 的 PSNR 等指标会大幅降低,推理时间和内存占用也会显著增加。
这揭示了信息过载对模型性能和资源消耗的直接因果关系:过多的冗余信息不仅拖慢了处理速度,更降低了最终的渲染质量。
用 " 信息瓶颈 " 理论,为前馈 3DGS" 减负 "
为了从理论层面理解并解决这一问题,ZIP Lab 和 Monash 团队引入了信息瓶颈(Information Bottleneck,IB)原理。
其核心思想是:从输入(X)中提取一个压缩表示(Z),使 Z 尽可能地保留与目标(Y)相关的信息,同时尽可能地压缩 X 中与 Y 无关的信息。
可以直观地理解为,IB 原理旨在最小化 " 压缩分数 "(即 Z 携带关于 X 的信息量),同时最大化 " 预测分数 "(即 Z 对于预测目标 Y 的有效信息量)。这一原理为前馈 3DGS 面临的 " 信息过载 " 这一 " 甜蜜负担 " 提供了理论上的 " 减负 " 之道。
基于对信息瓶颈原理的理解,ZPressor ——一个轻量级、且 " 架构无关 " 的模块,堂堂登场。
ZPressor 的核心功能在于高效地将多视图输入压缩成一个紧凑的潜在状态。这种压缩并非简单地丢弃信息,而是巧妙地保留了场景中的必要信息,同时有效剔除冗余,很好地解决了前馈 3DGS 模型长期以来面临的 " 信息过载 " 难题。
三步走,打造高效 " 信息压缩机 "
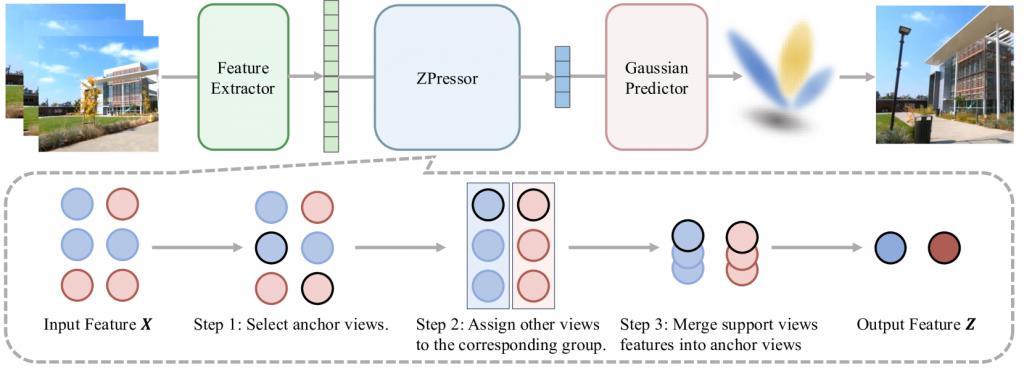
ZPressor 的精妙之处在于其将复杂的信息压缩过程分解为三个步骤,打造了一个高效的 " 信息压缩机 "。
第一步:锚点视图选择(Anchor View Selection)
ZPressor 首先通过 " 最远点采样 "(farthest point sampling)方法来选择锚点视图。这一迭代过程基于相机位置,确保所选的锚点在空间上具有多样性,并能最大限度地代表整个场景。
第二步:支持视图归属(Support-to-Anchor Assignment)
一旦锚点视图确定,每个剩余的支持视图都会根据相机距离被分配到其最近的锚点视图。精准的归属机制确保了支持视图中互补的场景细节能够与空间上最相关的锚点视图进行分组,保证了信息的 " 对口 " 融合,避免了无序。
第三步:视图信息融合(Views Information Fusion)
这是 ZPressor 实现信息压缩的关键步骤。它采用定制化的交叉注意力(cross-attention)模块进行信息融合。具体而言,从锚点视图中提取的特征充当 " 查询 "(query),而支持视图的特征则提供 " 键 "(keys)和 " 值 "(values)。
通过这种方式,支持视图的信息被有效地整合到锚点视图中,不仅捕捉了两者之间的关联性,还在保持紧凑性的同时避免了冗余。
最终,交叉注意力机制的运用,让这些互补信息真正 " 融会贯通 ",形成精炼而全面的 Z 态。
性能飙升,内存狂降,让前馈 3DGS" 脱胎换骨 "
ZPressor 对前馈 3DGS 模型产生了变革性的影响,这一点通过对 DepthSplat、MVSplat 和 pixelSplat 等经典模型在 DL3DV-10K、RealEstate10K 和 ACID 等大规模基准数据集进行的广泛实验中得到了充分验证。
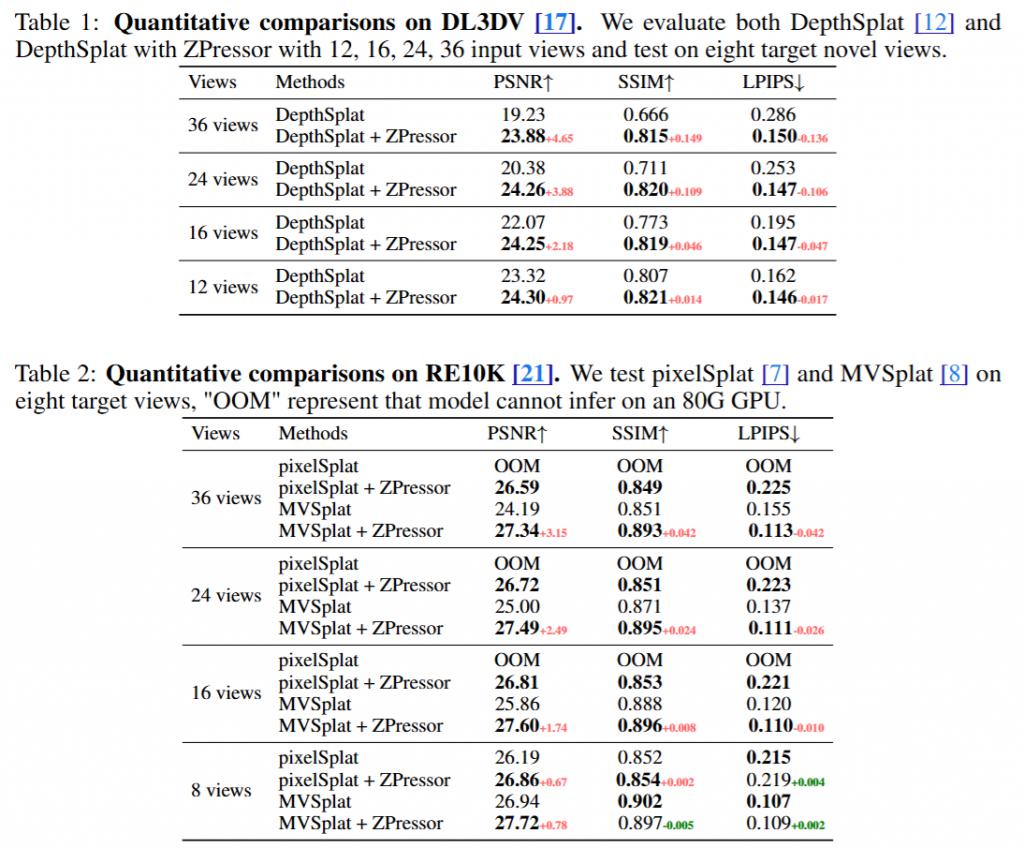
ZIP Lab 和 Monash 团队在 DL3DV 和 RE10K 上使用 12 个输入视图训练所有模型,并将其中 6 个设置为锚点视图,然后在 8 到 36 个不同数量的输入视图下评估它们。可以看到,随着输入视图数量的增加,ZPressor 的性能提升变得更加显著。
这是因为现有的前馈 3DGS 模型由于信息过载而难以处理密集输入,导致性能下降。而 ZPressor 能够通过冗余抑制压缩输入,同时保留关键信息,有效地缓解这一问题,提高模型鲁棒性,并在密集输入设置下保持优异性能。
此外,ZPressor 解决了现有模型在内存方面的重要障碍。例如,pixelSplat 在输入视图超过 8 个时就因 " 内存溢出 "(OOM)而无法运行,而 ZPressor 不仅使其能够成功运行至少 36 个视图,还在性能上带来了显著提升。

在 DL3DV 上关于密集输入条件(36 个视图)的定性比较结果表明,DepthSplat 由于密集视图中的冗余,表现不佳,而 ZPressor 有效压缩了这些信息,显著改善了视觉效果。

在 RE10K 上使用 36 个输入视图的定性比较结果表明,MVSplat 与 ZPressor 结合在所有情况下表现最佳。
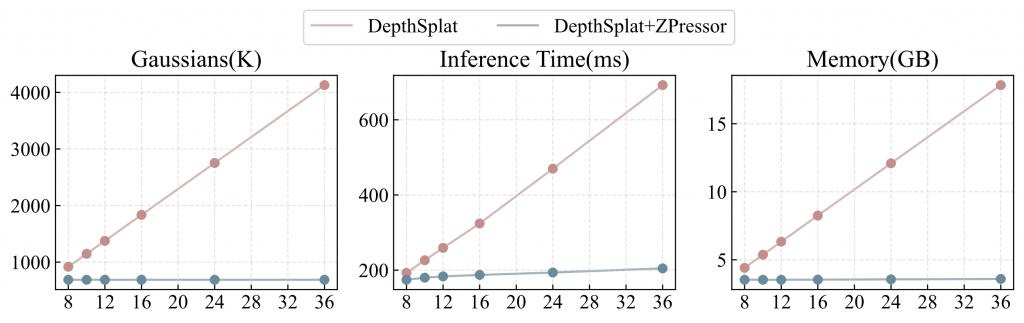
ZPressor 在效率方面的优势同样令人惊叹。它有助于在输入视图数量增加时,保持 3D 高斯数量、测试时推理延迟和峰值内存使用量的稳定。这与基线模型中这些指标呈线性增长的趋势形成了鲜明对比,后者很快就会变得难以承受。
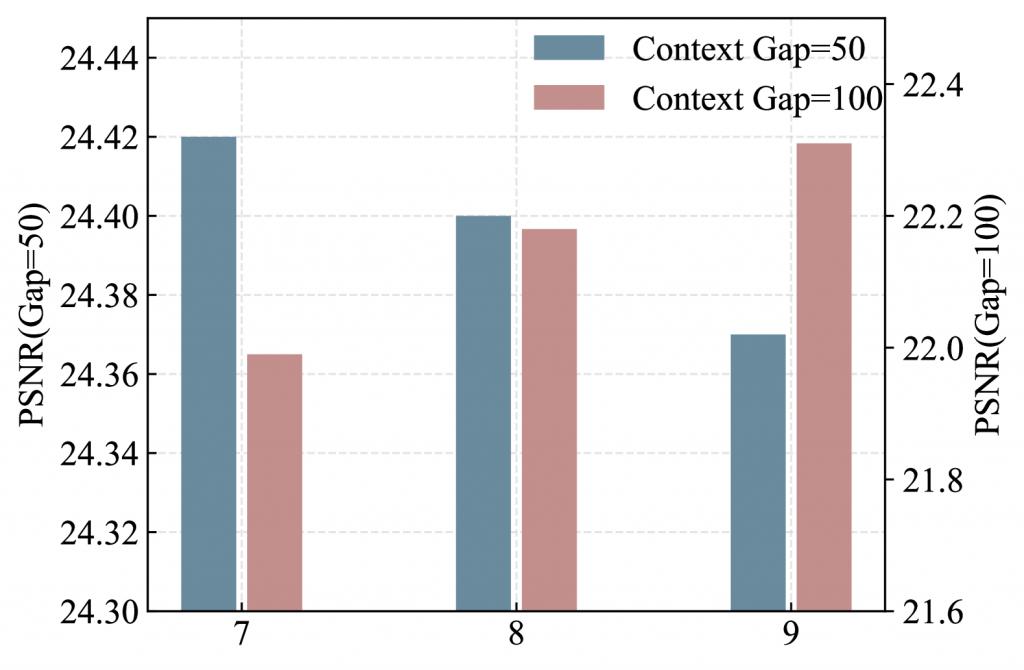
通过比较 ZPressor 在不同场景覆盖规模下的性能,可以看到,信息瓶颈是真实存在的,并且信息瓶颈在 ZPressor 中是可见的。在场景信息量小的条件下,额外的聚类会引入冗余;对于信息量更大的场景,信息瓶颈更高。这个结果突出了 ZPressor 在实现 IB 原则方面的有效性,并表明信息瓶颈在平衡压缩和信息保留方面至关重要。
ZPressor 不仅在适中视图设置下持续提升了现有基线模型的性能,更在密集输入场景下显著增强了模型的鲁棒性,同时保持了极具竞争力的效率(包括内存和速度)。

论文链接:https://www.arxiv.org/abs/2505.23734
项目主页:https://lhmd.top/zpressor
代码链接:https://github.com/ziplab/ZPressor
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
点亮星标
科技前沿进展每日见